Cell Ranger6.1, printed on 04/09/2025
Many experiments involve generating multiple 10x libraries processed through different Gel Bead-in Emulsion (GEM) Wells on the Chromium instrument. Depending on the experimental design, these could be replicates from the same set of cells, cells from different tissue/time points from the same individual, or cells from different individuals. The cellranger count, cellranger vdj, and cellranger multi pipelines process data from a single GEM well. The aggr pipeline aggregates the outputs from multiple runs of cellranger count/vdj/multi and performs analysis on the combined data.
| cellranger aggr is not designed for combining multiple sequencing runs from the same GEM Well (i.e., resequenced libraries). For that, pass the FASTQ files from multiple sequencing runs of the same GEM well to the count, vdj, or multi pipeline, as appropriate. |
The cellranger aggr command takes a CSV file specifying a list of cellranger vdj output files (specifically the vdj_contig_info.pb from each run), and performs clonotype grouping on the aggregated data. Consider two instances of B cell vdj pipelines using the sequencing data from two separate GEM wells prepared using the 10x Chromium™ platform, as described in this section.
$ cd /opt/runs $ cellranger vdj --id=Lib1 ... ... wait for pipeline to finish ... $ cellranger vdj --id=Lib2 ... ... wait for pipeline to finish ...
To aggregate these datasets, you need to create a CSV containing the following columns:
| Column Name | Description |
|---|---|
sample_id | Unique identifier for this input GEM well. This will be used for labeling purposes only; it does not need to match any previous ID assigned to the GEM well. |
vdj_contig_info | Path to the contig info file produced by cellranger vdj. For example, if you processed your GEM well by calling cellranger vdj --id=ID in some directory /DIR, this path would be /DIR/ID/outs/vdj_contig_info.pb |
donor | See the Glossary |
origin | See the Glossary |
There are three ways Cell Ranger can process the datasets depending on the combination of donor and origin values:
In addition to these CSV columns, cellranger aggr accepts additional columns containing library meta-data (e.g., vaccination status). These custom library annotations do not affect the analysis pipeline but can be visualized downstream in the Loupe V(D)J Browser.
You can either make the CSV file in a text editor, or create it in Excel and export to CSV. Continuing the example from the previous section, your Excel spreadsheet would look like this:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | sample_id | vdj_contig_info | donor | origin | VaccinationStatus |
| 2 | Sample1 | /opt/runs/Sample1/outs/vdj_contig_info.pb | D1 | pbmc_t0 | Pre-Vaccination |
| 3 | Sample2 | /opt/runs/Sample2/outs/vdj_contig_info.pb | D1 | pbmc_t1 | Post-Vaccination |
Required columns and experimental design information are shown here:
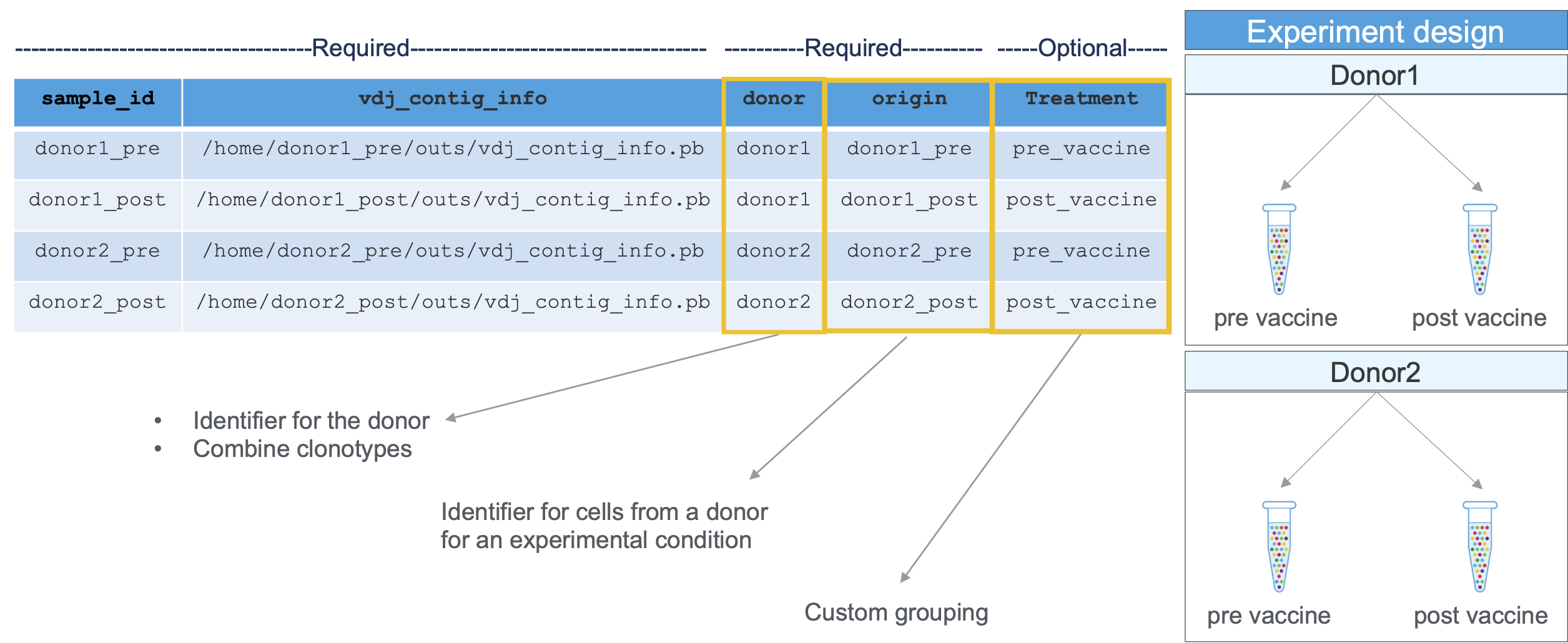
When you save it as a CSV, the result would look like this:
sample_id,vdj_contig_info,donor,origin,VaccinationStatus Sample1,/opt/runs/Lib1/outs/vdj_contig_info.pb,D1,pbmc_t0,Pre-Vaccination Sample2,/opt/runs/Lib2/outs/vdj_contig_info.pb,D1,pbmc_t1,Post-Vaccination
You can run the aggr pipeline as follows:
$ cd /opt/runs $ cellranger aggr --id=pre_post_vac_aggr --csv=aggr.csv
The pipeline will produce an error if the individual libraries were run using different V(D)J references or if the chain type (TCR or IG) in the individual libraries are inconsistent.
A successful run should conclude with a message similar to this:
- Copy of the input aggregation CSV: /opt/runs/pre_post_vac_aggr/outs/aggregation.csv
- count: null
- vdj_t: null
- vdj_b:
Aggregation metrics summary HTML: /opt/runs/pre_post_vac_aggr/outs/vdj_b/web_summary.html
Clonotypes csv: /opt/runs/pre_post_vac_aggr/outs/vdj_b/clonotypes.csv
Clonotype consensus FASTA: /opt/runs/pre_post_vac_aggr/outs/vdj_b/consensus.fasta
Annotations of filtered contigs with library metadata (CSV): /opt/runs/pre_post_vac_aggr/outs/vdj_b/filtered_contig_annotations.csv
Clonotype consensus annotations (CSV): /opt/runs/pre_post_vac_aggr/outs/vdj_b/consensus_annotations.csv
- V(D)J reference:
fasta:
regions: /opt/runs/pre_post_vac_aggr/outs/vdj_reference/fasta/regions.fa
donor_regions: /opt/runs/pre_post_vac_aggr/outs/vdj_reference/fasta/donor_regions.fa
reference: /opt/runs/pre_post_vac_aggr/outs/vdj_reference/reference.json
Pipestance completed successfully!
Each output file produced by cellranger aggr follows the format described in the Understanding Outputs section of the documentation, and it includes the union of all the relevant barcodes from each input jobs. The GEM well suffix of each barcode is updated to prevent barcode collisions, as described above.
Once cellranger aggr has successfully completed, browse the resulting summary HTML file in any supported web browser, open the .vloupe file in Loupe V(D)J Browser, or refer to the other output files to explore the data:
The cellranger aggr command can take a CSV file specifying a list of cellranger multi output directories, and perform aggregation on any combination of 5' Gene Expression, Feature Barcode (cell surface protein, antigen, or CRISPR) and V(D)J libraries that are present in the individual runs of cellranger multi.
Consider two multi datasets containing data from 5' Gene Expression and V(D)J libraries:
$ cd /opt/runs $ cellranger multi --id=Sample1 --csv=exp1.csv ... wait for pipeline to finish ... $ cellranger multi --id=Sample2 --csv=exp2.csv ... wait for pipeline to finish ...
To aggregate these datasets, you need to create a CSV containing the following columns:
| Column Name | Description |
|---|---|
sample_id | Unique identifier for this input GEM well. This will be used for labeling purposes only; it does not need to match any previous ID assigned to the GEM well. |
sample_outs | Path to the per sample outs folder generated by cellranger multi. For example, if you processed your GEM well by calling cellranger multi --id=ID --csv=exp1.csv in some directory /DIR , and the sample was called Sample1, this path would be /DIR/ID/outs/per_sample_outs/Sample1 |
donor | See the Glossary. This section describes how donor would affect the clonotype grouping in aggr. |
origin | See the Glossary. This section describes how origin would affect the clonotype grouping in aggr. |
cellranger aggr will auto-detect the presence of various libraries based on the structure and contents of the per sample outs folders. Apart from the change in the input CSV column (sample_outs instead of molecule_h5 or vdj_contig_info), the sections on aggregating outputs from cellranger vdj and aggregating outputs from cellranger count (depth normalization, batch correction etc.) applies here as well.
In addition to CSV columns described above, cellranger aggr accepts optional columns that may contain additional meta-data (e.g., vaccination status). These custom library annotations do not affect the analysis pipeline but can be visualized downstream in the Loupe V(D)J Browser.
You can either make the CSV file in a text editor, or create it in Excel and export to CSV. Your Excel spreadsheet might look like this:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | sample_id | sample_outs | donor | origin | VaccinationStatus |
| 2 | Sample1 | /opt/runs/Sample1/outs/per_sample_outs/Sample1 | D1 | pbmc_t0 | Pre-Vaccination |
| 3 | Sample2 | /opt/runs/Sample2/outs/per_sample_outs/Sample2 | D1 | pbmc_t1 | Post-Vaccination |
When you save it as a CSV, the result would look like this:
sample_id,sample_outs,donor,origin,VaccinationStatus Sample1,/opt/runs/Sample1/outs/per_sample_outs/Sample1,D1,pbmc_t0,Pre-Vaccination Sample2,/opt/runs/Sample2/outs/per_sample_outs/Sample2,D1,pbmc_t1,Post-Vaccination
You can run the aggr pipeline as follows:
$ cd /opt/runs $ cellranger aggr --id=pre_post_vac_aggr --csv=aggr.csv
The following page will take you to relevant sections on aggregating outputs from cellranger count (gene expression and Feature Barcode data). While the page is hosted on 3' Single Cell solution's section, they are equally applicable to 5' Immune Profiling solution as well:
Each GEM well is a physically distinct set of GEM partitions, but draws barcode sequences randomly from the pool of valid barcodes catalogued in the barcode whitelist. To track barcodes when aggregating multiple libraries, Cell Ranger appends an integer identifying the GEM Well to the barcode nucleotide sequence, and uses that nucleotide sequence and ID as the unique identifier. For example, AGACCATTGAGACTTA-1 and AGACCATTGAGACTTA-2 are distinct cell barcodes from different GEM wells, despite having the same barcode nucleotide sequence.
This number, which specifies which GEM well the barcode sequence originated from, is called the GEM well suffix. The numbering of the GEM wells reflects the order that the GEM wells were provided in the aggregation CSV.